

Künstliche Intelligenz (KI) hat das Potenzial, unser Leben in vielen Bereichen zu verändern. Sie kann dabei helfen, komplexe Probleme zu lösen, effizienter zu arbeiten sowie auch gänzlich neue Produkte und Dienstleistungen zu entwickeln. Allerdings birgt KI auch Risiken, wie Manipulation, Diskriminierung oder Datenschutz- und Urheberrechtsverletzungen.
Um diese Risiken zu minimieren und KI optimal zu nutzen, hat die Europäische Union kürzlich den EU-AI Act beschlossen.
Dieses Gesetz zur Regulierung von KI repräsentiert den ersten umfassenden Rechtsrahmen für KI weltweit. Er legt fest, wie KI-Systeme entwickelt und genutzt werden dürfen. So müssen sämtliche KI-Systeme künftig den EU-Vorschriften und dem neuen AI Act entsprechen. Das Gesetz soll noch 2024 in Kraft treten.
Ziele des EU-AI Acts
Die Ziele des EU-AI Acts sind unter anderem die Sicherstellung, dass Menschen durch KI-Systeme keine negativen Auswirkungen auf ihre Sicherheit, Gesundheit oder Grundrechte erfahren.
Während mögliche Manipulationen und Diskriminierungen verhindert werden sollen, wird es auch zur Festlegung ethischer Grundsätze für Entwicklung und Nutzung von KI kommen.
Schließlich soll auch mehr Transparenz und Rechenschaftspflicht bei der Entwicklung und Verwendung von KI entstehen. Das bedeutet, dass Nutzer und Nutzerinnen über die Funktionsweise von entsprechenden Systemen, verwendeten Daten sowie Risiken, die mit der Verwendung verbunden sind, informiert werden müssen.
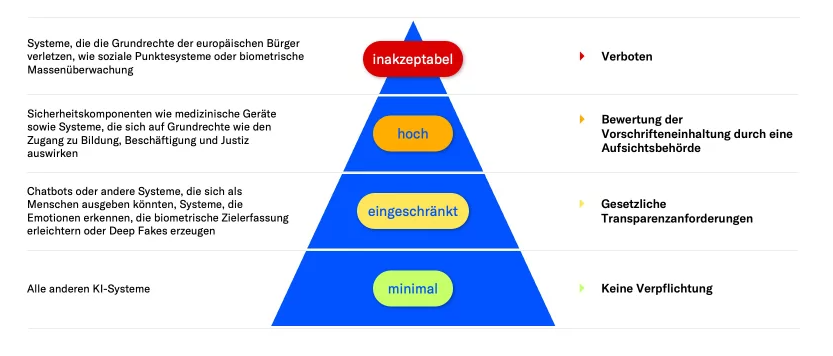
Risikokategorien des EU-AI Acts
Der EU-AI Act unterteilt KI-Systeme primär in drei Risikokategorien:
- wesentliches Risiko (inakzeptabel): Hierunter fallen KI-Systeme, die sich gravierend negativ auf die Grundrechte von Menschen auswirken können. Das betrifft etwa KI-Systeme, welche in kritischen Infrastrukturen eingesetzt werden, sowie auch Überwachungssysteme. Untersagt ist auch die Nutzung von KI-Systemen durch Behörden zur Bewertung oder Klassifizierung von Vertrauenswürdigkeit natürlicher Personen („Social Scorings“).
- erhebliches Risiko (hoch): Diese Stufe betrifft KI-Systeme, die immer noch ein hohes Risiko hinsichtlich negativer Auswirkungen auf Gesundheit, Sicherheit und Grundrechte von Menschen haben können. Darunter fallen zum Beispiel die Würde des Menschen, die Achtung des Privat- und Familienlebens, der Schutz personenbezogener Daten, die Freiheit der Meinungsäußerung und die Informationsfreiheit sowie die Versammlungs- und Vereinigungsfreiheit.
- geringes Risiko (eingeschränkt): KI-Systeme, die unter geringes Risiko eingestuft werden, haben keine negativen Auswirkungen auf Sicherheit, Gesundheit oder Grundrechte von Menschen. Dazu gehören etwa KI-Systeme, die zur Verarbeitung personenbezogener, nicht sensibler Daten eingesetzt werden. Der EU-AI Act fordert jedoch, dass auch KI-Systeme mit geringem Risiko sicher sein müssen, sofern sie in den Verkehr gebracht oder in Betrieb genommen werden.
Der EU-AI Act wird als Meilenstein der KI-Regulierung angesehen.
Die Idee ist, dass dieses Gesetz auch als globales Vorbild für andere Länder dienen soll.
Aber was bewirkt nun der EU-AI Act?
Prof. Stefan Woltran, Co-Direktor des Zentrums für Künstliche Intelligenz und Maschinelles Lernen (CAIML) der TU Wien erzählt im Interview was er vom neuen EU-AI Act hält, was er immer noch für problematisch empfindet und vieles mehr.
Herr Woltran, Sie beschäftigen sich schon sehr lange mit künstlicher Intelligenz und hatten auch bereits verschiedene Professuren an unterschiedlichen Fakultäten inne.
Empfinden Sie den aktuellen EU-AI Act auch als Meilenstein der KI-Regulierung und sollte er Ihrer Meinung nach als Vorlage für andere Länder gelten?
Woltran: Ja, ich denke tatsächlich, dass Europa mit dem AI Act Pionierarbeit geleistet hat. Es ist natürlich sehr herausfordernd, diese vielschichtige Technik, die jetzt eigentlich in alle Lebensbereiche eindringt, einem Regularium zu unterwerfen. Dementsprechend denke ich, dass diese grundlegende Idee, die KI-Systeme eher mal von der Anwendungsseite her zu klassifizieren und nicht notwendigerweise von ihrer darunterliegenden Methodik, eine gute Idee ist.
Die Einteilung in die vier Risikogruppen erscheint mir auch als eine sehr gute Sache. Ich denke auch, dass Lehren gezogen wurden, aus dieser Geschichte, was u.a. Social Media betrifft, wo zu lange im rechtsfreien Raum Dinge möglich waren und es im Nachhinein halt schwieriger ist, die Sachen zu ordnen.
Gerade die Large Language Models haben ja zu einem Verzögern, bzw. fast zu einem Scheitern des AI Acts geführt, weil diese in der Phase der Vorbereitung des EU-AI Acts ja noch gar nicht so am Schirm waren.
Welche Herausforderungen und Hürden sehen Sie bei der Umsetzung des EU-AI Acts?
Woltran: Es sind ja diese Transparenzauflagen relativ konkret ausformuliert. Man muss die Daten offenlegen, Maßnahmen treffen und belegen, Fairness und Bekämpfung von Diskriminierung berücksichtigen, gewisse Sicherheitsprüfungen sind notwendig und das muss auch zertifiziert werden.
Und was ich auch sehr spannend und gut finde ist, dass auch die Energieeffizienz eine Rolle spielt. Dass man das zumindest offenlegen muss, wieviel Rechenleistung z.B. gebraucht wird von diesen Anwendungen.
Wie bewerten Sie die Chancen und Risiken des EU-AI Acts für die Entwicklung von KI?
Woltran: Also z.B. die Nutzung von KI-Systemen Dritter ist etwas das fehlt im AI Act. Auch was in der untersten Risikoklasse eigentlich als kein oder geringes Risiko kategorisiert ist, nämlich Werbung, ist ein Thema. Also wenn KI für Werbung oder Empfehlungssysteme benutzt wird, besteht hier ein gewisses Gefahrenpotenzial hinsichtlich politischer Aspekte, weil dahinter eben das ganze Microtargeting liegt. Aber auch das Sammeln von Daten, um zielgerichtet Werbung anzuzeigen, ist nicht so harmlos, wie man vielleicht glaubt.
Wichtige Themen bezüglich denen Europa Chancen hätte, sind eben auch wie man das alles energieeffizienter machen kann, wie kann man einem LLM ein gewisses Regelwerk beibringen, ohne es umständlich trainieren zu müssen.
Gibt es weitere Maßnahmen, die Ihrer Meinung nach ergriffen werden sollten, um die Entwicklung und Nutzung von KI in Europa zu fördern?
Woltran: Ja, also was jetzt Maßnahmen zur Regulierung betrifft, gibt´s jetzt noch so eine Sache, wo Europa natürlich nicht so viel zum Mitreden hat, weil die ganz großen Konzerne nicht bei uns sind. Und zwar geht es um die Tendenz zur Monopolbildung in verschiedenen Bereichen. Das ist jetzt meine persönliche Meinung, aber ich halt es immer noch für sehr problematisch, dass die Daten, die KI-Modelle und die gesamte Userinterkation sozusagen, dass das alles in der Hand einiger Konzerne liegt. Das erscheint mir generell als ein sehr großes Problem. Und noch dazu die Infrastruktur. Eine derartige Situation gibt’s es in anderen Branchen nicht. Hier sollte noch mehr getan werden.
Was die Förderung betrifft, sehe ich aufgrund des neuen AI Acts kein großes Hindernis. Es gibt natürlich immer die Rufer, die meinen, das alles sei innovationshemmend, wobei man sich dazu auch fragen kann, bisher war er ja nicht in Kraft und wir sind als Europa hinten nach. Europa hat halt einen gewissen Standortnachteil, aufgrund der Mehrsprachigkeit, welche die Entwicklung von KI-Systemen aufwändiger macht. Das wird immer gern übersehen.
StudiVZ zum Beispiel war ein deutsches soziales Netzwerk, was eigentlich genau so groß war wie Facebook, es aber nicht geschafft hat über die Sprachgrenzen hinaus zu funktionieren und zu verbreiten. Vor allem fehlen in Europa auch die großen Kapitalgeber im Unterschied zu den USA. Wir haben hier eine ganz andere Kultur diesbezüglich, was nicht per se schlecht ist.
Am Ende sind aber genau jene Leute, die sich beschweren und jammern, diejenigen, die das finanzieren sollten.
Wie groß ist die Gefahr für Europa im Wettkampf über KI-Technologie im Vergleich zum Rest der Welt (primär USA, Israel, China, Russland, Indien) ins Hintertreffen zu gelangen? Die Sorge dabei besteht ja u.a. darin, dass etwaige UnternehmensgründerInnen sich dazu entschließen ihre Unternehmen im Ausland aufzubauen oder bereits bestehende Unternehmen überlegen abzuwandern?
Woltran: Ja, also man darf diese Frage selbstverständlich nicht kleinreden. Aber ich denk mir nur, es wird immer viel gejammert, ohne auch die positiven Beispiele aus Europa zu erwähnen. Es ist ja nicht so, dass in Europa nichts passiert. Es gibt natürlich hochinnovative Sachen wie Tomtom, die bei Navigationsgeräten führend waren. Es gibt DeepL, und noch zahlreiche andere Beispiele. Hier frag ich mich öfter, warum diese medial nicht mehr Aufmerksamkeit bekommen. Ich kann mir nicht vorstellen, dass das eine reine Regulierungsproblematik ist.
Was Europa vor allem auch gut kann, ist, dass es oftmals in gewissen Nischenprodukten führend ist. Beispiel Fertigung, Industrie. Dazu müsste man sich noch genauer überlegen, wie man in Zukunft vorgeht. Wir sind z.B. gut in Green AI.
Hier gäbe es noch viel Potenzial, es fehlt aber leider an konkreten strategischen Investments, oft auch am politischen Willen und am Wissen.
Wie schätzen Sie werden China und die USA auf die Regulierung der EU reagieren?
Woltran: Lobbying. China ist da eher entspannt, die schauen sich das wahrscheinlich nicht mal an.
Überlegt wird etwa auch Gesichtserkennung zumindest im militärischen Bereich zu ermöglichen oder in Ausnahmefällen wie etwa bei der Fahndung von Kriminellen zuzulassen. Halten Sie das für problematisch?
Woltran: Generell ja. Wenn diese Sachen gemacht werden können, dann werden sie vielleicht auch dort gemacht, wo es problematisch ist. Wobei der gesamte militärische Bereich ja nicht Teil des AI Acts ist. Was man auf staatlicher Ebene erlauben sollte und nicht ist aber eben eine hochpolitische Frage. Hier reden wir von Gesundheitsdaten, Überwachung, usw., immer wissend und sich dem Risiko bewusst, dass halt der Staat nicht immer in guten Händen sein muss. Nichtsdestotrotz fühle ich mich immer noch wohler, solche Daten beim Staat zu wissen, wo man eine gewisse Mitsprache hat und Regierungen gegebenenfalls auswechseln kann, als bei irgendwelchen großen Konzernen.
Manche Experten und Expertinnen meinen überhaupt der Begriff „Künstliche Intelligenz“ sei in erster Linie ein Marketingbegriff, weil man in den 60-er Jahren nach einem passenden Wort gesucht hat, um diese Systeme bekannt werden zu lassen.
Wie sehen Sie das? Passt die Definition künstliche Intelligenz für jene Dinge, die wir ebenso bezeichnen?
Woltran: Ja, also der Begriff ist hochproblematisch. Das ist eh eine alte Diskussion. Das war damals von Marketingdenken beeinflusst und aber auch um sich von Kybernetik abzugrenzen. Für die Informatik ist es eher untypisch, einen derart schwammigen Begriff einzuführen, der alles Mögliche umfasst. Um die ganze Breite des Feldes abzudecken, ist es wahrscheinlich gar nicht so leicht einen passenden Begriff zu finden.
Man hört immer wieder KI würde Probleme aufweisen, wenn andere ethnische Gruppen erkannt werden sollen und verweist dazu auf das Trainingsmaterial, welches dafür verantwortlich sein soll. Wäre es nicht normal und sogar wünschenswert, dass eine integre und realitätsnahe generative KI genau das wiedergibt, was in der realen Gesellschaft existent ist und auch derart wiedergibt, wie es dort eben verhandelt wird? Also auch so etwas wie Vorurteile, welche ja auch ihren natürlichen Sinn haben.
Würde das Bestreben einer KI einzuprogrammieren, sämtliche Vorurteile, die oft auf Wahrscheinlichkeiten basieren, strikt zu unterlassen und für totale Gleichheit zu sorgen, nicht eine gezielte Verzerrung der Realität bedeuten?
Woltran: Also diese Bias Geschichte ist eine allgegenwärtige und die Frage, ob man das umgehen will oder nicht ist in verschiedene Bereichen wahrscheinlich auch unterschiedlich zu beurteilen. Ich glaube auch nicht, dass man KI-Systeme gezielt belügen oder absichtlich mit verzerrten Daten füttern könnte. Es wird eher in die Richtung gehen – und das ist das, was uns ausmacht – dass wir ja auch mit Daten arbeiten. Alles, was an unbewussten Entscheidungen getroffen wird, funktioniert ja ähnlich wie bei diesen KI-Systemen, wie auch dann, wenn wir bewusst über Sachen reflektieren. Wir haben vielleicht mal eine Bauchgefühl, wissen aber, dass es ein gewisses Regelwerk gibt, welches es zu berücksichtigen gilt. Das versucht man dann abzuwägen. In diese Richtung muss es gehen.
Im Endeffekt braucht es eine gewisse Kombination von Methoden, sodass die Systeme die Realität abbilden und diese aber auch proaktiv in ein Regelwerk einbinden können.
Es kann aber auch nicht der Weisheit letzter Schluss sein, dass man versucht, KI-Systemen gezielt in eine Richtung formen will, die vielleicht auch fragwürdig ist. Idealer wäre es, wenn die KI-Systeme einerseits den Datenaspekt, die Datengetriebenheit erfüllten und andererseits mit einem Weltmodell, einem symbolischen Modell umgehen könnten und damit ihre eigenen Antworten überprüfen, hinterfragen und erklärbar machten.
Interessant ist etwa auch etwas, das sich Automation Bias nennt. Das bedeutet, dass Menschen dem Resultat von Computern immer sehr stark vertrauen. Man geht von einer hundertprozentigen Wahrscheinlichkeit, also von Sicherheit aus. Wenn man jetzt diese KI-Systeme hat, die auf gewissen Wahrscheinlichkeiten beruhen, dann ist halt keine Sicherheit, bzw. keine hohe Wahrscheinlichkeit mehr gegeben, um von tolerablen Ergebnissen zu sprechen.
Eine ganz wesentliche Frage ist auch jene nach dem Urheberrecht. Wie unterscheidet sich diese Problematik jetzt z.B. von Suchmaschinenergebnissen?
Im WorldWideWeb werden ja auch bereits unzählige Informationen frei zugänglich gemacht. Könnte man KI-Textgeneratoren, bzw. dessen EntwicklerInnen nicht einfach dazu verpflichten Verweise und Quellen anzugeben?
Woltran: Das ist ein ganz wichtiger Punkt. Wenn es jetzt so ist wie bei ChatGPT, dass alle möglichen Dokumente verwendet werden, die irgendwie zugänglich sind und „zugänglich“ da ja relativ großzügig ausgelegt wurde, dann ist das natürlich schon eine andere Dimension. Urheberrechtlich wird das jedenfalls schwierig und technisch kaum umsetzbar, weil die Sprachmodelle nicht dazu gebaut wurden, um dies zu gewährleisten.
Zur Frage von Transparenz und KI: Glauben Sie, es wird uns Menschen in Zukunft überhaupt noch möglich sein, KI-generierte Inhalte von nicht KI-generierten Inhalten zu unterscheiden? Wenn nicht, wäre das problematisch?
Woltran: Die Problematik befindet sich auf mehreren Ebenen, die man ausverhandeln muss. Eine Sache, die oft gar nicht sonderlich Beachtung findet, ist die Frage, wie man reagiert, wenn wissenschaftliche Erkenntnisse durch KI-Systeme weiterentwickelt werden. Wenn man das dann selbst weder verstehen noch lehren können wird. Das ist eine Frage der Wissenschaftstheorie.
Zu KI-generierten Inhalten: Also ich halte es generell für ein Problem, dass man jeglichen Content, dem man im Netz begegnet, misstrauisch gegenüber sein muss.
Alexandra Ebert von mostly ai meinte in einem ZIB-2 Interview, dass der EU-AI Act die Problematiken des Erkennens von Fake News, etc. nicht abdecke. Aber wäre nicht gerade das in Anbetracht der aktuellen politischen, militärischen und gesellschaftlichen Entwicklung der wichtigste Punkt von allen?
Woltran: Ja, das fehlt ein bisschen. Ob die entsprechenden Informationen jetzt falsch sind oder nicht, ist ja schon egal eigentlich. Es reicht ja schon, wenn die Leute in eine gewiss Richtung getrieben werden, Stichwort Filterblasen.
Zur Person:
Univ.Prof. Dipl.-Ing. Dr.techn. Stefan Woltran ist Professor für Formal Foundations of Artficial Intelligence am Institut für Logic and Computation und leitet seit 2020 den Forschungsbereich Databases and Artificial Intelligence. Seine Forschung untersucht die formalen Grundlagen logik-basierter Methoden der künstlichen Intelligenz, insbesonders in Bezug auf Komplexitätsanalyse und Algorithmus-Design. 2013 wurde er mit dem FWF START Preis ausgezeichnet und 2018 zum Fellow der European Association for Artificial Intelligence ernannt.
Infobox:
Der EU-AI Act ist ein vom europäischen Parlament verabschiedetes Gesetz zur Regulierung von Künstlicher Intelligenz.
Die Ziele des EU-AI Act beziehen sich auf Sicherheit und Vertrauenswürdigkeit, auf Fairness und Ethik sowie auf Transparenz und Gerechtigkeit von KI.
Der EU-AI Act unterscheidet zwischen drei Risikostufen von KI-Systemen: inakzeptabel (z.B. Software zur Gesichtserkennung), hoch (z.B. Algorithmen, die über Kreditwürdigkeit entscheiden), eingeschränkt (z.B. Chatbot-Systeme).
Wissenswertes:
Large Language Models (LLM) ist eine Art Sprachmodell, das sich durch seine Fähigkeit auszeichnet, menschenähnliche Sprache für allgemeine Zwecke zu verstehen, zu generieren und darauf zu reagieren. Es kann Textverarbeitungsaufgaben durchführen, Fragen beantworten, Konversationen führen, Texte generieren und vieles mehr.
Microtargeting bezeichnet die gezielte Kommunikation mit Nachrichten, die auf bestimmte Charakteristika einer Person zugeschnittenen sind, um damit beispielsweise das Wahl- oder Kaufverhalten zu beeinflussen. Das kann in sozialen Netzwerken, Internetnachrichtenkanälen oder auch direkt an der Haustür geschehen.
studiVZ war ein soziales Netzwerk für Studenten und Studentinnen. Im November 2005 gegründet, war es neben den später folgenden Plattformen schülerVZ und meinVZ ein Angebot der VZ Netzwerke.
DeepL ist ein Onlinedienst für maschinelle Übersetzung. Betrieben wird er von der Aktiengesellschaft DeepL SE mit Sitz in Köln.
Kybernetik ist nach ihrem Begründer Norbert Wiener die Wissenschaft der Steuerung und Regelung von Maschinen und deren Analogie zur Handlungsweise von lebenden Organismen und sozialen Organisationen
ChatGPT ist ein Chatbot, der künstliche Intelligenz einsetzt, um mit Nutzern und Nutzerinnen über textbasierte Nachrichten und Bilder zu kommunizieren. Er nutzt moderne maschinelle Lerntechnologie, um Antworten zu generieren, die natürlich klingen und für das Gespräch relevant sein sollen.